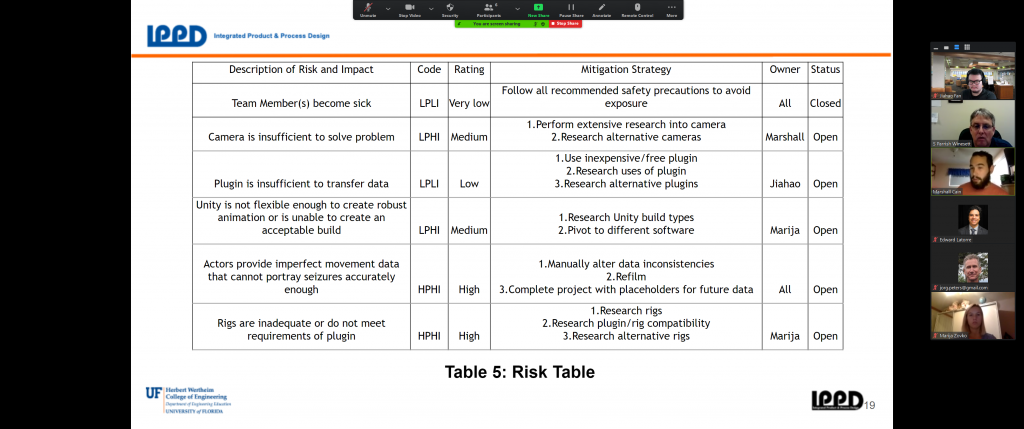
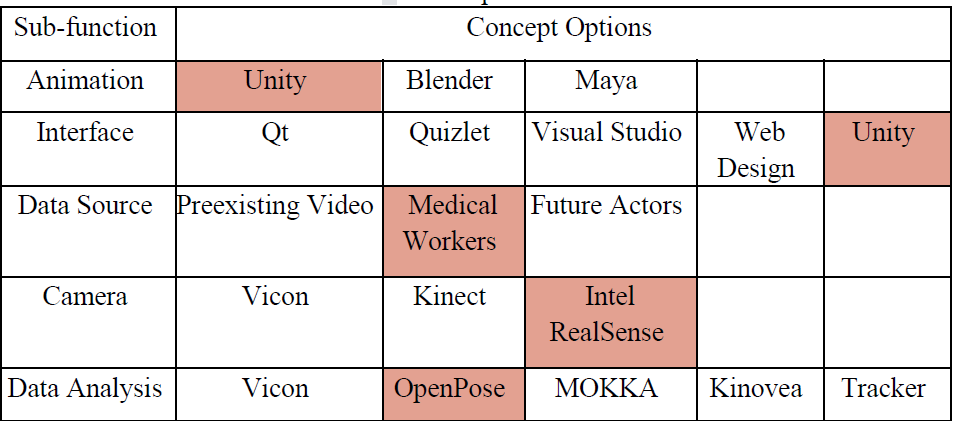
So you have seen our concept generation table from the previous post. You may wonder why we choose certain solution over the other ones. This post will give you a detailed explaination.
Functions
For our system model, we have a few actors, as well as the I/O that is moved by each function. For our initial architecture, here is a description of the functions, as well as their actors and I/O:
- Dr. Winesett and Medical Workers will provide reference footage to the RealSense camera.
- The RealSense camera will provide video and depth data to Unity.
- Unity will interpret and animate the data, sending the new data to the System.
- The User will provide input to the System, such as choosing an answer option.
- The System will provide information to the User in the form of education, I/O response, and assessment feedback.
- The System will provide a software package to the Distributor.
- The Distributor will provide the same software package to the User.
For concept generation, we included 5 sub-functions with multiple concept choices.
The reasons
The first sub-function is Animation, which is the interpretation and animation of the data sent by the camera. The concept choices are the software that can be used. We chose Unity because there are many plugins for taking 3D video information into Unity, as well as tools for an interface.
The second sub-function is Interface, which is the UI system that the User will interact with to provide input and receive feedback. The concept choices are the assets or software that can be used. The choices are Qt, Quizlet, Visual Studio, Web Design, and Unity. We chose Unity because it can also handle Animation. This means we can build the entire system in the same software. Unity can create both executables and web applets, making it flexible.
The third sub-function is Data Source, which is the original data sample(s) that Unity will have to interpret into animation. The choices are Preexisting Video, Medical Workers, and Future Actors. Preexisting Video is a video of seizures that can be provided by Dr. Winesett. Medical Workers are volunteers that understand the types of seizures that would be acting for a 3D camera. Future Actors would also be acting for a 3D camera, but a post-design phase. We chose Medical Workers because it would be an immediate source of information and it includes a depth channel. The Preexisting Video does not include depth, so we would need different software to interpret it and the result may not be as robust. We may still need to pivot and design the system to work with future 3D data from future actors if the data from the Medical Workers is insufficient.
The fourth sub-function is the Camera, which is the 3D camera that will be used to record the motion data. The choices are Vicon, Kinect, and Intel RealSense. We chose the Intel RealSense depth camera because it was a good price and the Kinect is no longer in production. It also had a good number of software options and plugins that would allow the data it produces to be transferred to Unity easily.
The last sub-function is Data Analysis, which is the software that will be used to synthesize the data from the 3D Camera and move it into Unity. The options are Vicon, OpenPose, MOKKA, Kinovea, and Tracker. Vicon is a suite of software from Vicon that would work well with the Vicon camera. OpenPose is a free, open-source project that can be easily used with the Intel RealSense camera to interpret the footage and bring it into Unity. MOKKA (Motion Kinematic & Kinetic Analyzer) is free software that would provide data from a 3D camera. Kinovea is a paid software that would work well with the Intel RealSense camera and would be able to transfer that data to Unity. Tracker is a free video analysis tool that would work well with 2D footage to create 3D data. We chose OpenPose because it is free, we chose to use the RealSense camera, and we chose to use Unity.