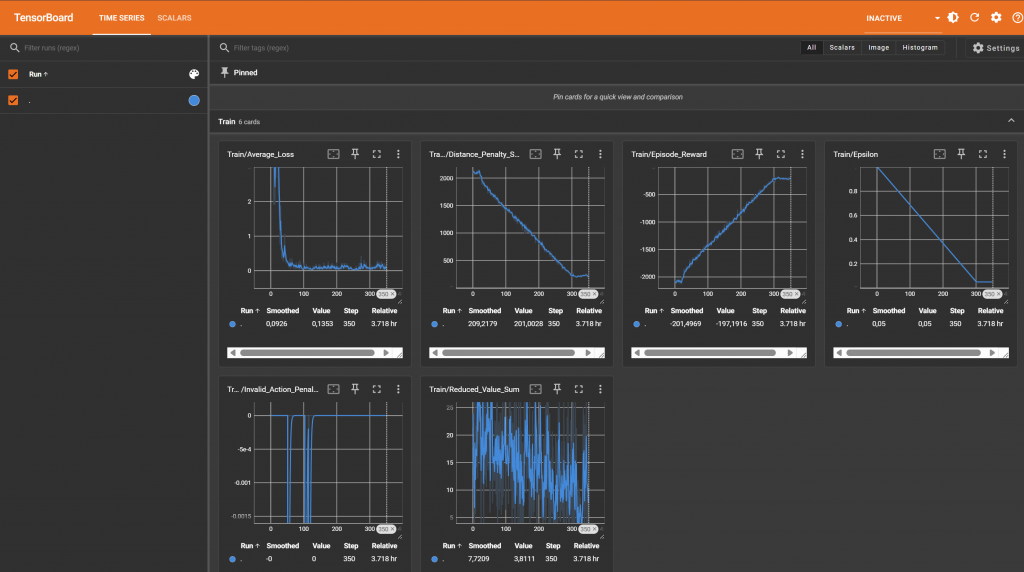
This week, the GPU testing, benchmarking, and RL learning team all advanced. The GPU testing team got TensorRT working with dynamic batch sizes and found that it was much faster than PyTorch! The benchmarking team finished the lightweight runner but realized that the position of the satellite must be considered per scenario so more edits must be made in the simulator’s configuration and the lightweight runner. The RL learning team tried to run multiple training jobs in parallel via AWS and unfortunately crashed the EC2. They have since made the pivot to train sequentially.
The image below is a full day of movement from the satellite. During our conversations about if the reward should be penalized for pictures in the dark, the team had to take a step back and realize that a polar sun synchronous orbit ensures that the satellite will never be on the dark side of the Earth!

Aside from progress made in teams, the entire team came together to discuss which metrics should be considered to determine success of the trained agent over the heuristic methods. A great discussion was had on which metrics should be maximized and which should be minimized for the best strategy (hopefully the trained agent). We must continue having conversations in our Slack channel and at our weekly meetings with MRSL to formalize what success is.