This week, our team met together in UF’s Nuclear Sciences Building to sit down and make sure that everyone on the team has a good understanding of our project’s code base.

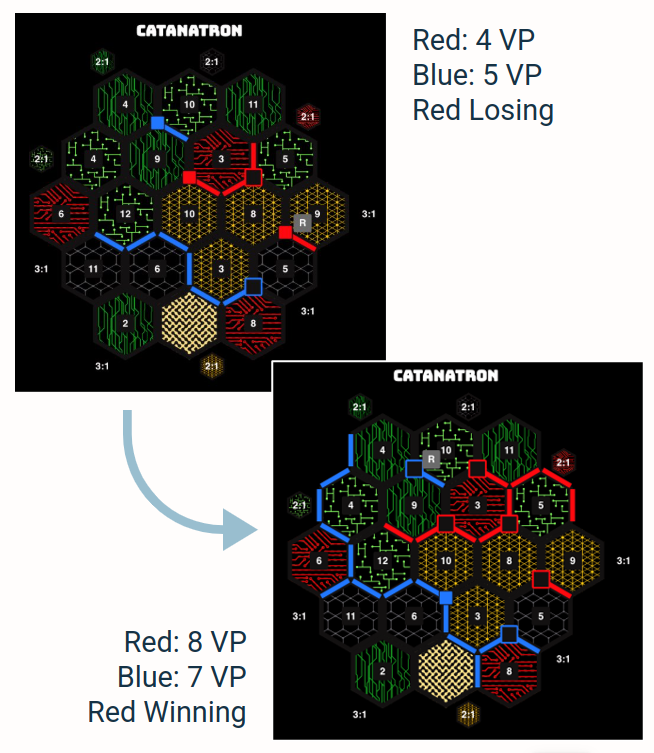
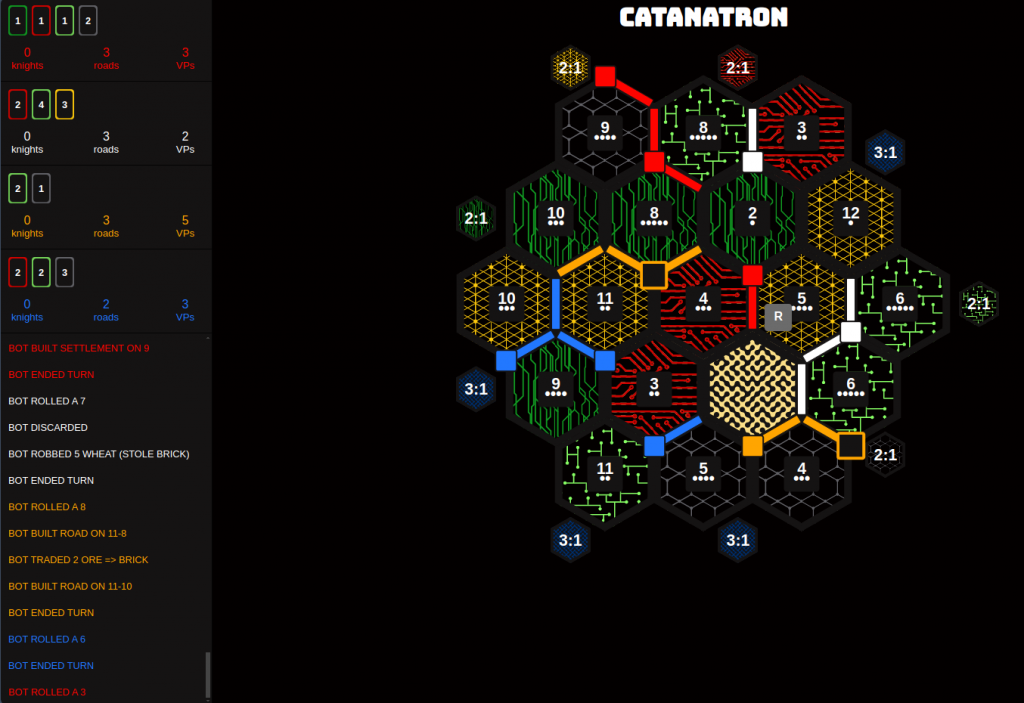
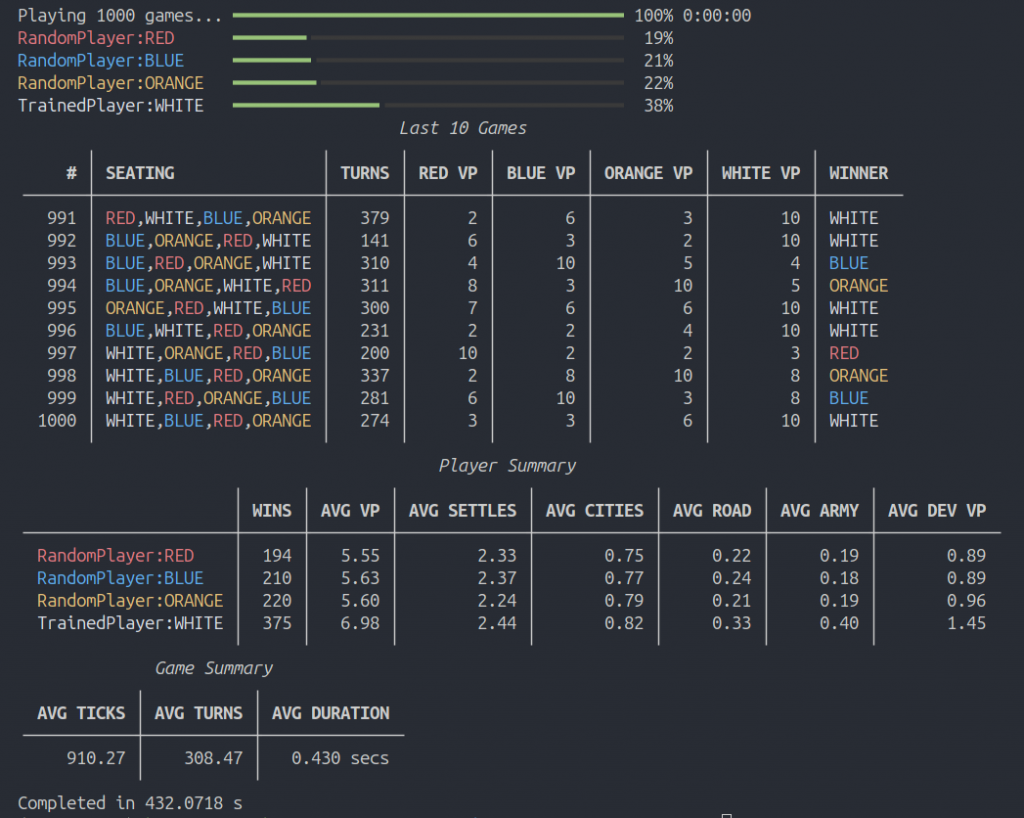
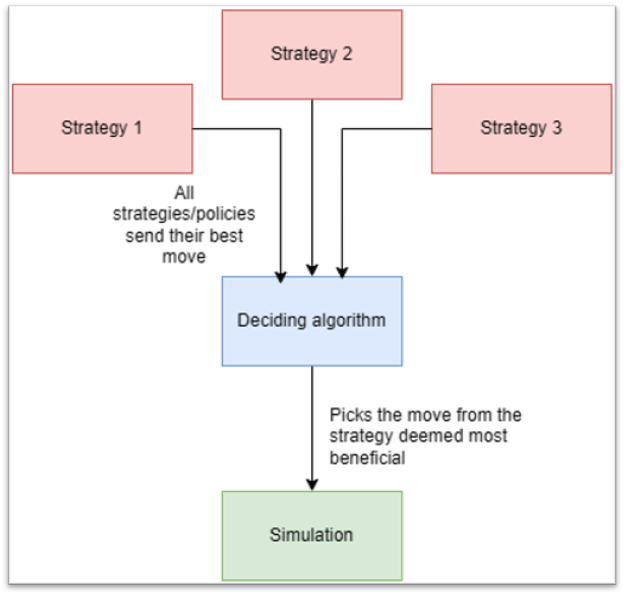
During this meeting, we went over our current project’s design. Since we started using Catanatron as our simulation, we’ve developed a series of “value function players”. These players do not use reinforcement learning algorithms but rather a value function to evaluate each possible action on their turn. These players are vastly superior to the “random choice” and “weighted random choice” players, who both take actions based on the result of a random number generator. The value function players should prove to be useful when testing and training our AI models.
Additionally, we went over our current framework for training a model. As mentioned back in the fall semester, we intend to train our models using HiPerGator, a supercomputer located at UF. Since we have a lot of potential algorithms to test and a lot of games to play, we have to find a way to train and test these models as efficiently as possible.
Finally, we went over our plans for the next week. Jason will be working on adding multiprocessing to our project. Han, Cathy, and Andres will be researching ways to build our reinforcement learning model. Brian will be working on the UI, making sure that humans can play against the models we create.
That’s all for now! See you next week!