It has been a wonderful year with IPPD! We’ve gone through a long journey to get here. We researched different board games to pick one suitable for our project. We visited CAE in Orlando to give our PDR presentation. We explored different simulations for our game before eventually settling on one at the end of the fall semester. We went through multiple peer reviews and QRB presentations to learn how we can improve our project. Finally, we ended things off by presenting an agent that managed to beat us in Catan.
During our last IPPD class last Tuesday, Team Tactica presented its project at IPPD’s Final Design Review event!

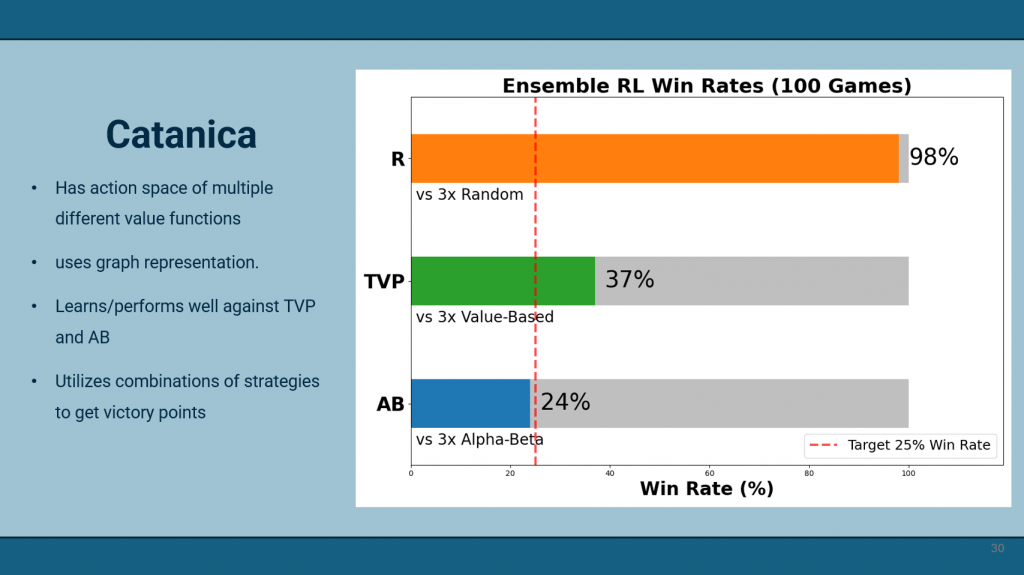
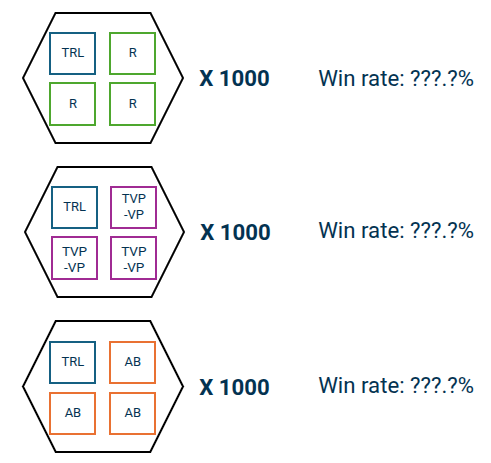
As part of the event, we got to hear from keynote speakers on the history of industry-sponsored engineering design programs and on lifelong learning. Afterward, we gave our presentation to our sponsors and coaches, showing our GUI, our process for building an AI agent, and the results of our different agent designs. As discussed in previous posts, our most promising agent is one that reduces our action space by selecting from a set of strategies rather than choosing actions directly.

Unfortunately, our original target win rate of 50% in all tests was a bit too ambitious, so we prioritized demonstrating the usefulness of ensemble models and Graph Neural Networks (GNNs). We’ll be sure to document our findings in our upcoming research paper.
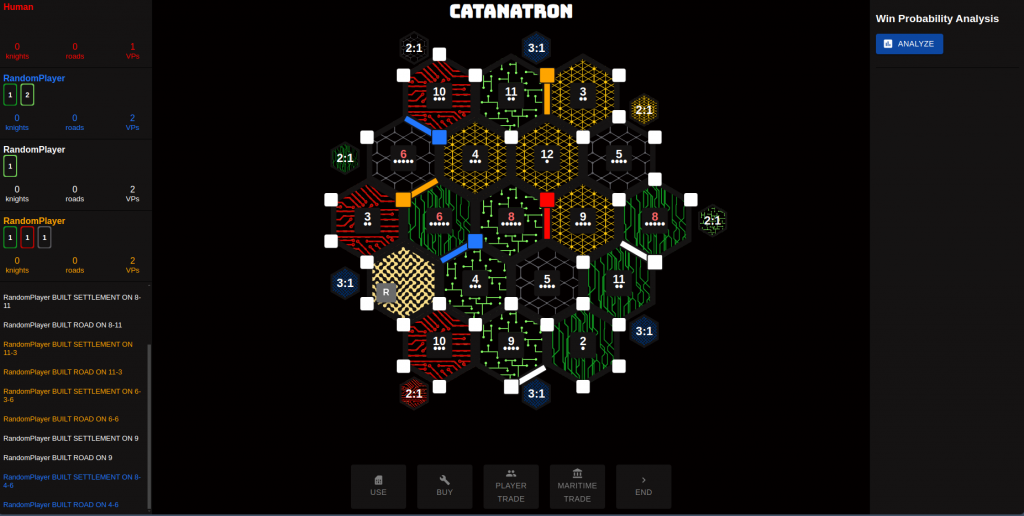
We had two computers at our table with Catanatron running. Those who were familiar with the game of Catan got to sit at one of our chairs and try it for themselves. Our liaison even got to try it, and our agent managed to beat him! Some of us were able to play against the model as well.


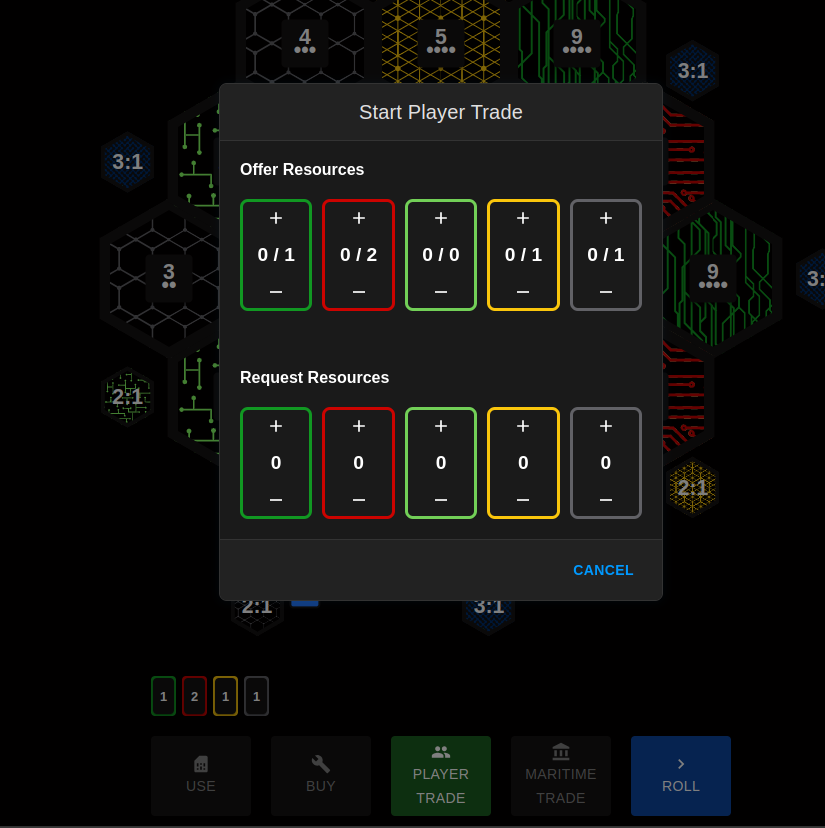
We noticed a few interesting behaviors of our model. For one, it never seems to offer trades and almost always rejects trades offered to it. Despite our efforts to implement trading, it seems our model couldn’t fully comprehend it. Brian and Han played against the model a few times and even lost a few times. However, Han was eventually able to pick up on the agent’s strategy and exploit it.
During the event, viewers also got to see our video, which played in the background during the public showcase. We tried to aim for something humorous to appeal to a wide audience:

If we had more time to continue the project, we would try more strategies for reinforcement learning, train against more opponent types, and improve our models’ explainability. Explainability is a common issue with deep learning since the model is like a “black box”, which makes it difficult to judge how a model arrives at a decision. We could improve our game log to show what strategies our model is taking and even use a Large Language Model (LLM) to analyze these strategies.
As the project comes to a close, some of us will continue to work on our research paper to hopefully present it at the Interservice/Industry Training, Simulation and Education Conference (I/ITSEC). Beyond that, however, we’ll all be going our separate ways. It’ll be sad to see things end, but for us, it’s the only the start of our future careers in engineering!
We are Team Tactica, and we thank you for reading!