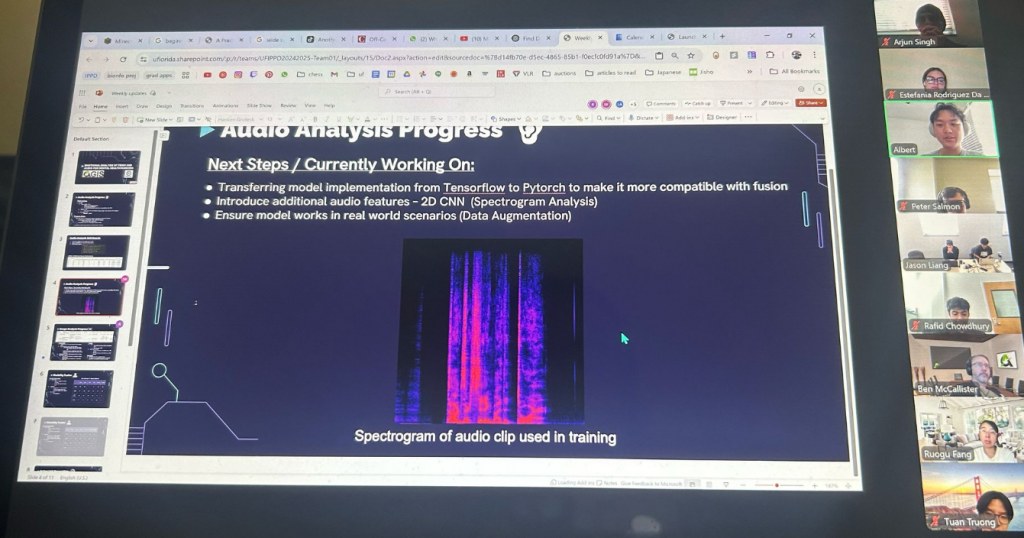
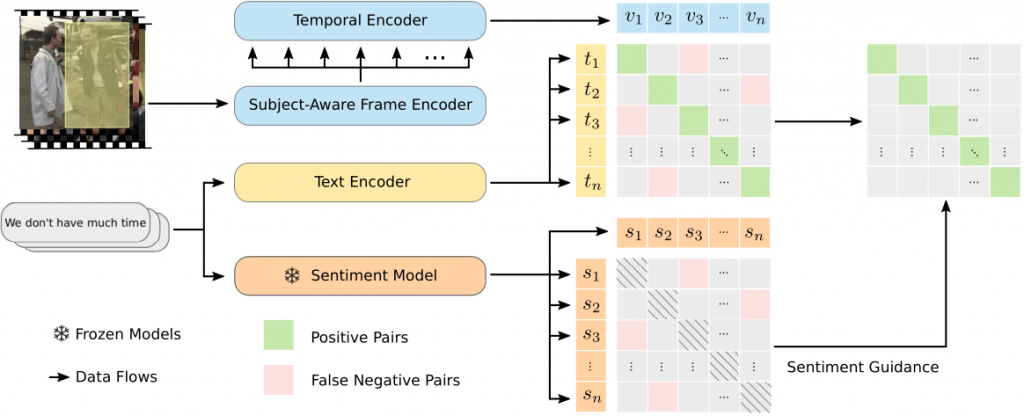
Our audio team successfully migrated the model from Tensorflow to Pytorch and completed grid search optimization for the 1D CNN hyperparameters. The video team focused on CLIP development, working with the text encoder and improving zero-shot accuracy while also running grid searches for optimal CLIP hyperparameters. We achieved an important milestone by implementing late fusion with our current CLIP and 1D MFCC CNN models, evaluating their combined performance on CMU-MOSEI test data.
For the coming week, we’ll focus on comprehensive performance documentation, including detailed data samples from our training and testing sets. The audio team will showcase audio samples from each dataset, while the video team explores bounding box implementation, black and white image processing, and cross-dataset training. We’re expanding our focus on generalizability by conducting cross-dataset training and testing, incorporating multimodal datasets, and utilizing training data that better represents our use case. Finally, we’ll be integrating text and AU analysis components into our fusion model.



{kind=link}