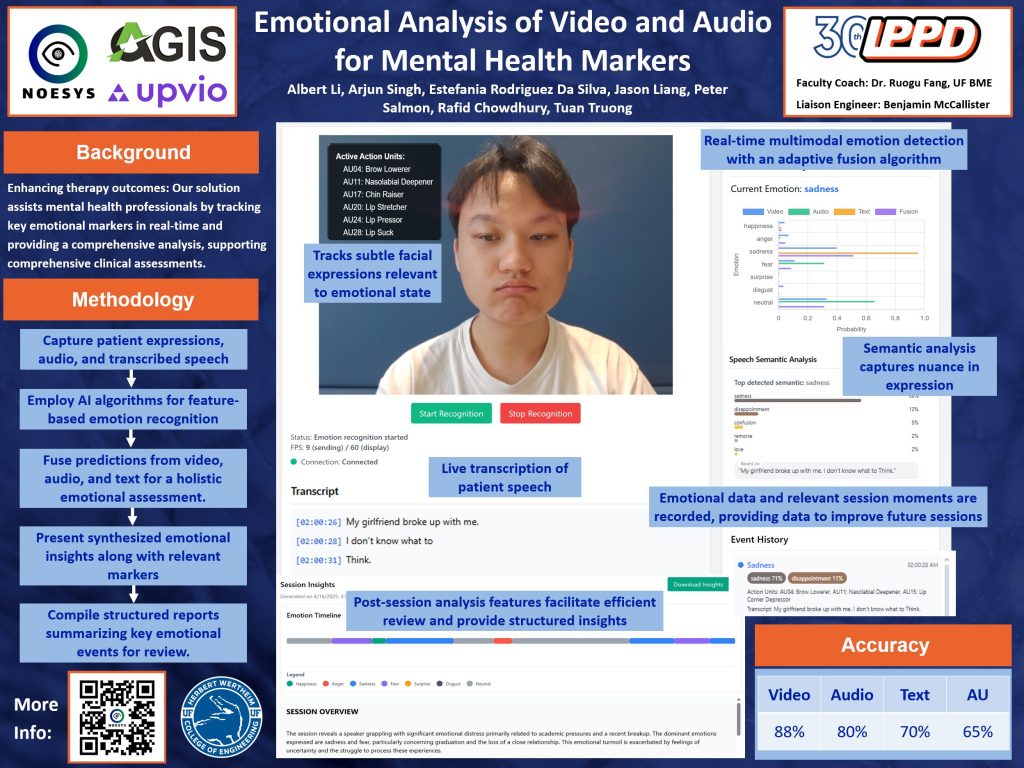
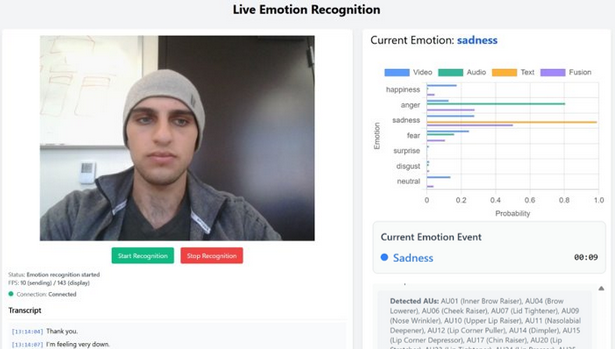
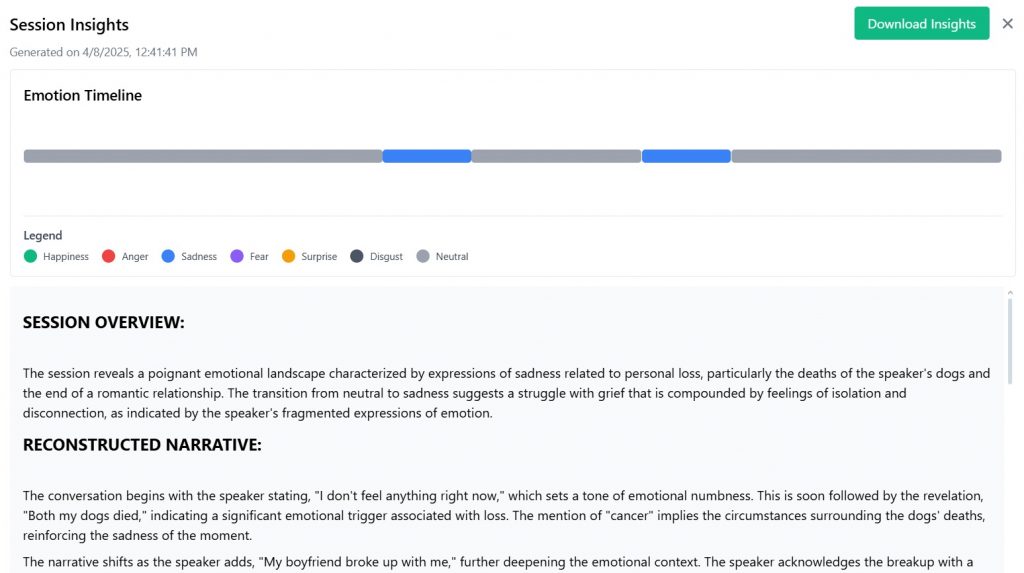
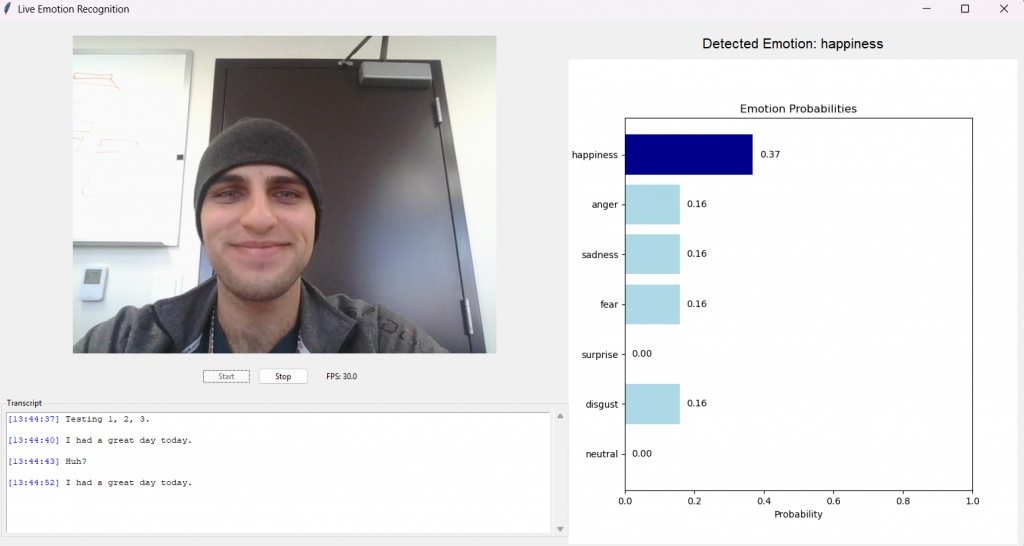
Team Noesys has successfully completed our Final Design Review presentation this week! We presented our emotional analysis system for AGIS AI at the Reitz Union, showcasing our web application’s real-time capabilities in detecting emotions across audio, video, and text modalities. The presentation highlighted our journey from concept to functional prototype. Check out our poster and video below for more information.
As we wrap up the IPPD experience, we want to express our gratitude to our liaisons at AGIS AI, our coach, and the IPPD staff who made this project possible. The past two semesters have been both challenging and incredibly rewarding. We’re proud of what we’ve accomplished as Team Noesys and excited about the potential impact of our work. Thanks for reading our blog, and farewell from all of us at Team Noesys!