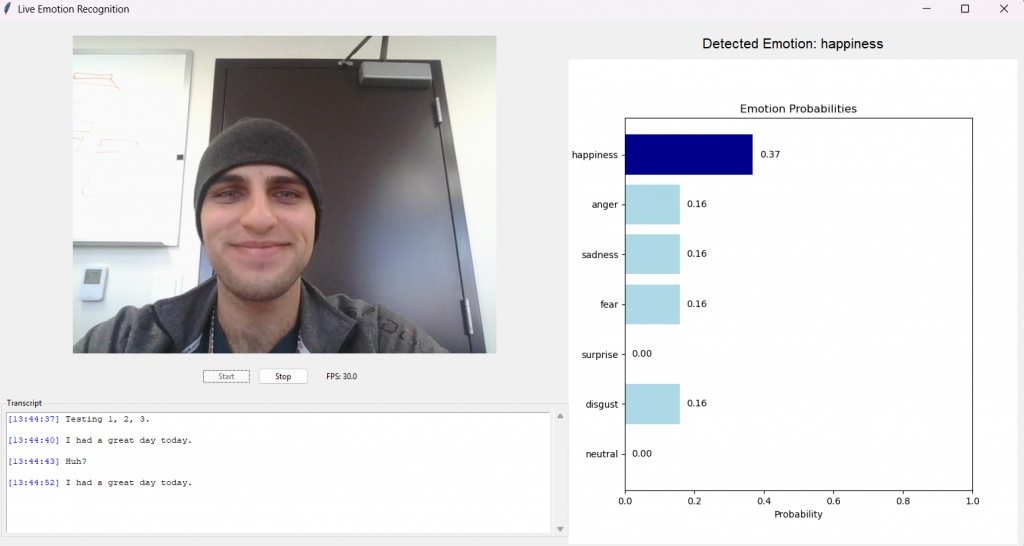
This week, our team built our first real-time demo incorporating all modalities with late fusion. As the user speaks, the demo captures visual, audio, and textual information, and integrates the predictions from each of these models to determine the likelihood of each emotion. We were pleasantly surprised at how low the latency was, as classifications were made within 1-2 seconds of the spoken expression. This program also logs the transcript and emotional predictions with time stamps in CSV format, facilitating smooth implementation of post-processing features in the future.
We’ve made some progress towards correcting biases in predictions resulting from class imbalances in our training data, but there’s still more work to be done. Our audio team implemented weighted loss function in our fine-tuning, but imbalances still remain. Our plan is to next try balanced sampling to see if this alleviates the issue.
Our vision modality team received the weights for EmotionCLIP, an implementation of OpenAI’s CLIP model fine tuned for emotional classification. The performance on our test datasets does still need improvement, so we’ve been trying to find ways to adapt it for our use case.